
告別整數,迎接 UUIDv7!
探索不同資料庫索引的權衡取捨:從循序整數、隨機生成的 UUID,到基於時間的識別碼和最新最棒的 UUIDv7
作者: Gordon Chan
Buildkite 過去用兩個鍵值儲存資料。我們用循序主鍵來有效索引,也用 UUID 次要鍵值供外部使用。即將到來的 UUIDv7 標準兩者兼具;它按時間排序的 UUID 主鍵可同時用於索引和外部使用。本文將帶您了解 Buildkite 如何決定採用 UUIDv7 作為主鍵。我們會探討資料庫索引的取捨:從循序整數、隨機 UUID,到時間識別碼。
什麼是 UUID?
UUID(通用唯一識別碼)是不需中央機構或與其他方協調就能獨立產生的唯一識別碼。隨著大型現代應用程式和系統的分布式特性,UUID 格式的識別碼越來越常被用作資料庫鍵值。不像循序整數識別碼需要協調才能在分布式資料庫中確保全局唯一性,UUID 免除了協調的負擔,讓它在分片資料庫環境中更受歡迎。
UUID 也比循序整數識別碼更有優勢。UUID 不可預測,能公開使用而不洩露敏感內部資訊和統計數據。UUID 也難以猜測,除了存取控制檢查外,還能多一層防護,防止「不安全的直接物件參考」( Insecure Direct Object Reference ) 漏洞。
UUID 的隨機性和 128 位元的長度讓重複的機率趨近於零,所以我們可以認為 UUID「實際上」是唯一的。然而,標準非時間排序 UUID(例如 v4)的隨機性,如果用作主鍵,可能會造成資料庫效能問題。這問題常被稱為「資料庫索引局部性差」。
使用雙重識別碼
幾年前,因為非時間排序 UUID 效能問題很大,我們決定標準化使用循序整數 ID 作為主鍵。我們也在資料庫表格上使用 UUID 作為次要識別碼。涉及表格聯結的查詢會使用循序整數外鍵,通常比隨機 UUID 外鍵效能更好。外部和面向客戶的部分都使用 UUID(例如在 API 和網址中)。所有團隊都標準化這種雙重識別碼方法,以提升工程師生產力。
了解索引局部性差的問題
連續產生的非時間排序 UUID 值不是循序的。隨機產生的值不會在資料庫索引中聚集,所以插入會在隨機位置執行。這種隨機插入會影響 B 樹等常見索引資料結構及其變體的效能。
Buildkite 產品的特性代表最近的資料比舊資料存取更頻繁。用非循序識別碼時,最新資料會隨機分散在索引中,缺乏聚集性。所以,從大型資料集擷取最新資料需要遍歷很多資料庫索引頁面,導致快取命中率低(快取成功滿足的請求數和收到的請求數相比)。相反地,用循序識別碼時,最新資料會按邏輯排列在索引最右邊,對快取更友善。
改進 UUID 的運作方式
索引局部性問題在過去十多年來產生許多實作方式。常見的解決方案是使用基於時間的唯一識別碼。識別碼的第一部分(前綴)是可排序的時間戳記,讓這些識別碼能按循序(和聚集)順序插入索引資料結構。因為產生的識別碼是循序的,所以插入效能和插入循序整數識別碼差不多。
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| time stamp | | random |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+根據實作方式,識別碼的其餘部分可以完全隨機產生,也可以是機器循序並用機器/分片編號編碼。例如 ULID、Instagram 的 ShardingID、Twitter 的 Snowflake 和 Mastodon 修改版的 Snowflake。
實驗基於時間戳記的 UUIDv4
2022 年,一個新的依時間排序的 UUID 標準提案開始受到關注,UUIDv7 規範成為 RFC 網際網路草案。
當時,Buildkite 開始試用與 UUIDv4 相容的依時間排序 UUID。
- 前 48 位元(原本是隨機的)變成時間戳記。
- 版本位元維持不變,讓依時間排序的 UUID 可以被視為一般的 UUIDv4 值。
- 維持 v4 相容性對某些 Buildkite 客戶很重要。實驗中,Buildkite 嘗試將版本設為「7」,卻發現這會讓一些驗證 UUID 但還不了解 UUIDv7 的下游客戶系統出錯。
這個改變(以及 6 週內其他幾項改變)讓主要資料庫的 WAL(預寫式日誌)速率降低了 50%。寫入 IO 也降低了。WAL 速率降低讓團隊能輕鬆設定讀取副本和執行其他資料庫遷移任務。
介紹 UUID 版本 7
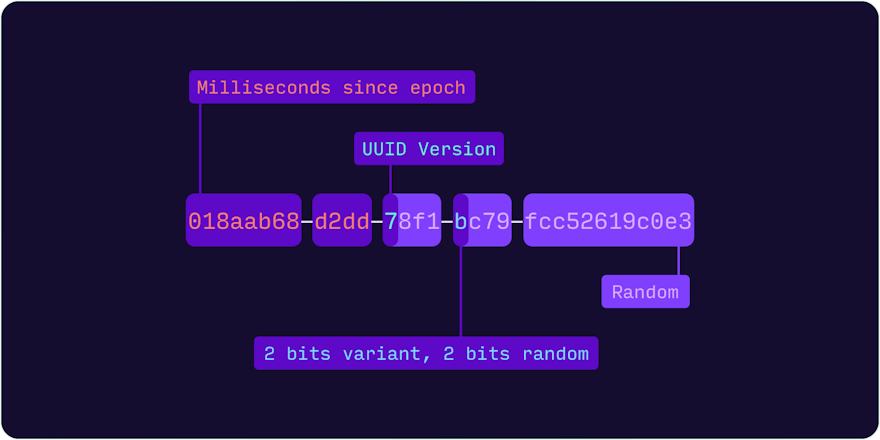
UUID 版本 7(UUIDv7)是依時間排序的 UUID,它以毫秒精度將 Unix 時間戳記編碼到最重要的 48 位元。和所有 UUID 格式一樣,用 6 位元表示 UUID 版本和變體。其餘 74 位元是隨機產生的。因為 UUIDv7 依時間排序,所以產生的值實際上是循序的,也就解決了索引局部性問題。
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| unix_ts_ms |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| unix_ts_ms | ver | rand_a |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
|var| rand_b |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| rand_b |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+UUIDv7 依時間排序的特性,讓它的資料庫效能比隨機前綴的 UUIDv4 好很多。 2nd quadrant 部落格的一篇文章比較了隨機 UUID 和循序 UUID,顯示寫入和讀取效能都有提升。
UUIDv7 繼續遵循標準 UUID 格式,所以實際上可以把它們當作其他 UUID 使用。這項相容性讓我們可以使用現有的 Postgres UUID 欄位,輕鬆地將欄位從儲存 UUIDv4 值轉換為 UUIDv7。
遷移到 UUIDv7 作為主鍵
今年初,我們決定在新表格中使用 UUIDv7 作為主鍵(取代循序整數 ID)。
Buildkite 工程師目前正依組織 ID 將 Pipelines 資料庫分片。我們很快發現,在分布式資料庫環境中,使用整數 ID 作為主鍵會變成負擔。在資料庫之間確保遞增整數主鍵唯一性,協調和解決方法都不理想。隨著 UUIDv7 標準穩定且接近定稿,Buildkite 決定在新表格中使用 UUIDv7 作為主鍵。
使用 UUIDv7 作為主鍵就不需為新表格協調識別碼產生。我們也不用第二個整數識別碼欄位,簡化了應用程式邏輯。這些 UUID 可以在 API 中外部使用,也可以內部用作外鍵。
考慮的替代方案和權衡
我們團隊考慮過很多方法,包括 Instagram 的 ShardingID 實作和 Shopify 的複合主鍵實作,我們也考慮保留我們自己訂製的依時間排序 UUIDv4。但是,我們研究的方法都很新穎,可能很複雜,加上 UUIDv7 很可能成為未來的標準,所以我們決定用 UUIDv7。
UUID 有 128 位元,是其他 64 位元方案的兩倍長。雖然有一些額外的儲存空間開銷,但相較於資料庫列其他部分的儲存空間,以及遷移的好處,這點開銷對我們來說很小。
展望未來
Buildkite 目前正依組織 ID 將 Pipelines 資料庫分片。目前我們不需要將資料庫分片編號編碼到識別碼。但值得一提的是,如果未來需要,UUIDv8(大致允許任何內容)可以用來將分片編號加到識別碼中。
新的 UUID RFC 正在最後審查階段,我期待 UUIDv7 成為 IETF 提議標準。



