
PostgreSQL 最惱人的部分
PostgreSQL 的 MVCC 實作方式不好,但它仍然是我們最愛的 DBMS。

本文與 Bohan Zhang 共同撰寫,最早刊登於 OtterTune 網站。
資料庫種類繁多(截至 2023 年 4 月已有 897 種)。這麼多系統,如何選擇實在傷腦筋!網路社群往往會集體決定新應用程式的預設選項。 2000 年代,由於 Google、Facebook 等科技新星採用 MySQL,它成了主流選擇。 2010 年代,MongoDB 因「非持久性寫入」而「網路規模化」,成為新寵。近五年來,PostgreSQL 變成網路社群最愛的資料庫管理系統(DBMS)。它確實有其優點!可靠、功能豐富、可擴充,很適合大多數的營運工作負載。
雖然 OtterTune 團隊很愛 PostgreSQL,它還是有些缺點。我們不想寫另一篇吹捧 PostgreSQL 多棒的文章,而是要談它一個很糟糕的缺點:多版本並行控制( MVCC )的實作方式。卡內基美隆大學的研究和我們在 Amazon RDS 上優化 PostgreSQL 資料庫的經驗都顯示,它的 MVCC 實作比 MySQL、Oracle、Microsoft SQL Server 等其他常用的關聯式 DBMS 都差。Amazon 的 PostgreSQL Aurora 也一樣有這些問題。
本文將深入探討 MVCC :它是什麼、PostgreSQL 如何實作,以及為什麼它很糟糕。 OtterTune 的目標是幫您減少資料庫的煩惱,所以我們一直在思考如何解決 PostgreSQL 的 MVCC 問題。下週的文章將會介紹 OtterTune 如何自動管理 RDS 和 Aurora 資料庫中 PostgreSQL 的 MVCC 問題。
什麼是多版本並行控制?
DBMS 中的 MVCC 目的是盡可能讓多個查詢同時讀寫資料庫而不會互相干擾。 MVCC 的基本概念是 DBMS 永遠不會覆寫現有資料列。 DBMS 會為每一(邏輯)列維護多個(實體)版本。應用程式執行查詢時,DBMS 會根據版本順序(例如:建立時間戳記)決定要讀取哪個版本。這樣一來,多個查詢可以讀取舊版本,而不會被更新資料列的查詢擋住。查詢看到的是交易開始時的資料庫快照(快照隔離)。如此就不用使用顯式記錄鎖定,避免讀取器在寫入器修改同一項目時被鎖住。
David Reed 1978 年的麻省理工學院博士論文《分散式資料庫系統中的並行控制》是第一篇描述 MVCC 的出版物。第一個商業化實作 MVCC 的 DBMS 是 1980 年代的 InterBase。之後,近二十年來幾乎所有支援交易的新 DBMS 都實作了 MVCC 。
開發支援 MVCC 的 DBMS 時,系統工程師需要做幾個設計決策。大致來說,就是以下幾點:
- 如何儲存對現有資料列的更新。
- 執行時期如何找到查詢所需的正確資料列版本。
- 如何移除過期的版本。
這些決策環環相扣。 PostgreSQL 在 1980 年代對第一個問題的處理方式,導致了我們至今仍需面對的後兩個問題。
我們用以下的電影資訊表格來舉例說明。每列包含電影名稱、上映年份、導演和一個做為主鍵的唯一 ID,並在電影名稱和導演上建立次要索引。以下是用來建立表格的 DDL 指令:
CREATE TABLE movies (
id INTEGER PRIMARY KEY GENERATED ALWAYS AS IDENTITY,
name VARCHAR(256) NOT NULL,
year SMALLINT NOT NULL,
director VARCHAR(128)
);
CREATE INDEX idx_name ON movies (name);
CREATE INDEX idx_director ON movies (director);表格包含一個主索引(movies_pkey)和兩個次要 B+Tree 索引(idx_name、movies_pkey)。
PostgreSQL 的多版本並行控制
Stonebraker 在 1987 年的系統設計文件中提到,PostgreSQL 從一開始就設計成支援多版本。 PostgreSQL 的 MVCC 方案的核心概念看似簡單:查詢更新表格中的現有資料列時,DBMS 會複製該列,並將變更套用到新版本,而不是覆寫原來的資料列。我們稱之為「追加式」版本儲存方案。但接下來會說明,這種方法會對系統其他部分造成一些影響。
多版本儲存
PostgreSQL 將表格中所有資料列版本都儲存在同一個儲存空間。更新現有資料列時,DBMS 會先從表格中取得一個空位來儲存新版本。接著它會將目前版本的內容複製到新版本,再將修改套用到新版本。以下的例子說明應用程式執行更新查詢,將《少林與武當》的上映年份從 1985 年改成 1983 年的過程:
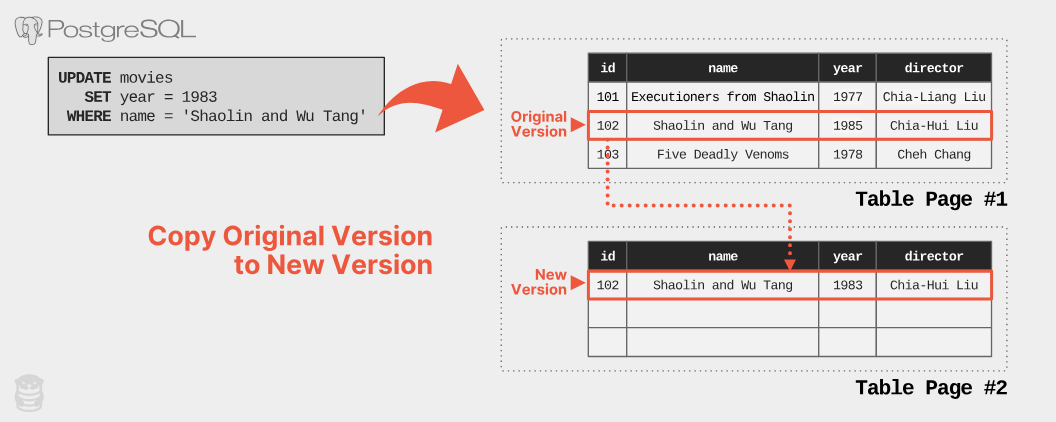
現在有了兩個代表同一個邏輯列的實體版本,DBMS 需要記錄這些版本的演變過程,以便日後找到它們。 MVCC DBMS 會建立「版本鏈」,像單向連結串列一樣。版本鏈只有一個方向,以減少儲存和維護的負擔。這表示 DBMS 必須決定使用哪種順序:「由新到舊」( N2O )或「由舊到新」( O2N )。 N2O 的話,每個版本都指向它的前一個版本,鏈的頭永遠是最新的版本。 O2N 的話,每個版本都指向它的下一個版本,鏈的頭是最舊的版本。 O2N 不需要 DBMS 在每次修改資料列時更新索引,使其指向新版本。但 DBMS 查詢時可能需要更多時間才能找到最新版本,因為它可能需要走過很長的版本鏈。包括 Oracle 和 MySQL 在內,大多數 DBMS 都實作 N2O 。只有 PostgreSQL 使用 O2N (除了 Microsoft SQL Server 的 In-Memory OLTP 引擎)。
下一個問題是 PostgreSQL 如何決定要記錄哪些版本指標。 PostgreSQL 中每個資料列的標頭都包含一個指向下一個版本的資料列 ID 欄位( t_tcid )(如果是最新版本,則指向自己)。因此,如下例所示,當查詢要求最新版本時,DBMS 會走過索引,找到最舊的版本,然後沿著指標找到所需的版本。
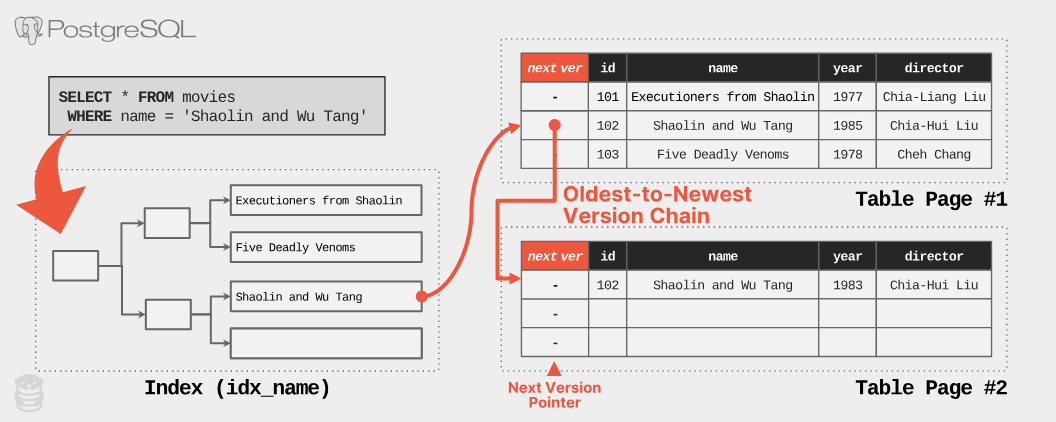
PostgreSQL 開發人員很早就發現它的 MVCC 方案有兩個問題。第一,每次更新都複製整個資料列很耗資源。第二,只為了找到最新版本(大多數查詢都只需要最新版本)而走過整個版本鏈很浪費。當然還有清理舊版本的問題,我們稍後再談。
為了避免走過整個版本鏈,PostgreSQL 會在表格索引中為每個實體版本新增一個項目。這表示,如果一個邏輯列有五個實體版本,索引中就會有五個對應的項目!下例中,idx_name 索引包含了不同頁面上每個「少林與武當」列的項目。這樣就可以直接存取最新版本,不用走過長長的版本鏈。
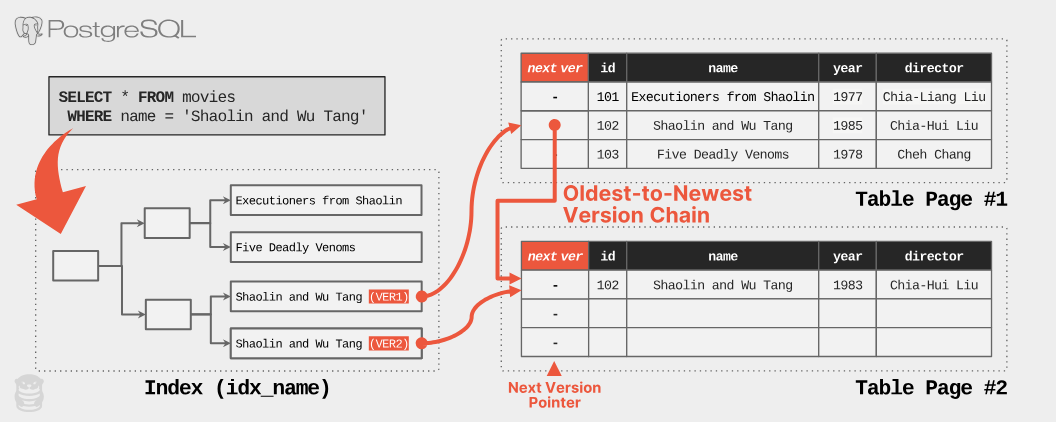
為了減少磁碟 I/O,PostgreSQL 會盡量在新版本與舊版本相同的磁碟頁面(區塊)建立副本,避免新增多個索引項目,以及將相關版本儲存在多個頁面。這種優化稱為「 Heap-Only Tuple ( HOT )更新」。如果更新沒有修改任何被表格索引參考的欄位,而且新版本與舊版本儲存在同一個資料頁面(如果該頁面還有空間),DBMS 就會使用 HOT 更新。更新後,索引仍然指向舊版本,查詢會走過版本鏈來取得最新版本。正常運作時,PostgreSQL 會移除舊版本來縮短版本鏈,進一步優化這個過程。
版本清理
我們已經知道 PostgreSQL 在應用程式更新資料列時會建立副本。下一個問題是系統如何移除舊版本(稱為「死亡資料列」)。 1980 年代的 PostgreSQL 並不會移除死亡資料列。當時的想法是保留所有舊版本,讓應用程式可以執行「時間旅行」查詢,查看資料庫在特定時間點的狀態(例如:查詢上週結束時的資料庫狀態)。但是,從不移除死亡資料列表示表格在刪除資料列後大小不會縮小。這也表示經常更新的資料列會有很長的版本鏈,進而拖慢查詢速度,除非 PostgreSQL 新增索引項目,讓查詢可以快速跳到正確的版本,而不是走過整條鏈。但這又表示索引會變大,速度變慢,還會增加記憶體的負擔。希望您現在能理解為什麼這些問題都互相影響。
為了克服這些問題,PostgreSQL 使用清理程序來清除表格中的死亡資料列。清理程序會循序掃描自上次執行以來修改過的表格頁面,找出過期的版本。如果某個版本對所有活躍的交易都不可見,DBMS 就會將其視為「過期」。這表示目前沒有任何交易正在存取該版本,未來的交易會使用最新的「活躍」版本。因此,移除過期版本並回收空間是安全的。
PostgreSQL 會根據設定檔定期自動執行清理程序(自動清理)。除了影響所有表格清理頻率的全域設定外,PostgreSQL 也允許針對個別表格設定自動清理。使用者也可以透過 VACUUM SQL 指令手動觸發清理程序來優化資料庫效能。
為什麼 PostgreSQL 的 MVCC 最糟糕
坦白說:如果現在要設計新的 MVCC DBMS ,絕對不應該 用 PostgreSQL 的方式(例如:搭配自動清理的追加式儲存)。 2018 年的 VLDB 論文(又稱「史上最佳 MVCC 論文」)中,我們沒有找到其他 DBMS 像 PostgreSQL 這樣實作 MVCC 。它的設計是 1980 年代的產物,早於 1990 年代日誌結構系統模式的興起。
以下說明 PostgreSQL MVCC 的四個問題,以及 Oracle、MySQL 等其他 MVCC DBMS 如何避免這些問題。
問題一:版本複製
在 MVCC 的追加式儲存方案中,查詢更新資料列時,DBMS 會將所有欄位複製到新版本,無論查詢只更新一個欄位或所有欄位都一樣。可以想見,追加式 MVCC 會造成大量資料重複和儲存空間需求增加。這表示 PostgreSQL 比其他 DBMS 需要更多記憶體和磁碟空間來儲存資料庫,導致查詢速度變慢,雲端成本增加。 MySQL 和 Oracle 並不會複製整個資料列來建立新版本,而是儲存新舊版本之間的差異(就像 git diff 一樣)。使用差異表示,如果查詢只更新一個有 1000 個欄位的表格中的一個欄位,DBMS 只會儲存該欄位的變更記錄。 PostgreSQL 則會建立一個包含該變更欄位和其他 999 個未變更欄位的新版本。我們會忽略 TOAST 屬性,因為 PostgreSQL 處理 TOAST 屬性的方式不同。
曾有人嘗試改良 PostgreSQL 的版本儲存實作。 EnterpriseDB 在 2013 年啟動了 zheap 專案,打算用差異版本取代追加式儲存引擎。可惜的是,最後一次官方更新是在 2021 年,這個計畫似乎已經不了了之。
問題二:表格膨脹
PostgreSQL 中的過期版本(即死亡資料列)也比差異版本佔用更多空間。雖然 PostgreSQL 的自動清理最終會移除這些死亡資料列,但在寫入頻繁的工作負載下,死亡資料列的累積速度可能比清理的速度還快,導致資料庫不斷擴張。 DBMS 執行查詢時必須將死亡資料列載入記憶體,因為死亡資料列和活躍資料列都混雜在頁面中。無限制的膨脹會拖慢查詢效能,因為 DBMS 執行表格掃描時需要更多 IOPS 和記憶體。此外,死亡資料列也會造成優化器統計資料不準確,導致查詢計畫不佳。
假設電影表格有 1000 萬列活躍資料列和 4000 萬列死亡資料列, 80% 的表格都是過時資料。也假設表格的欄位比我們顯示的還多,平均每列大小為 1KB 。在這種情況下,活躍資料列佔用 10GB 的儲存空間,死亡資料列佔用約 40GB ;表格總大小為 50GB 。查詢執行完整表格掃描時,PostgreSQL 必須從磁碟讀取所有 50GB 的資料並載入記憶體,即使大部分都是過時的資料。雖然 PostgreSQL 有保護機制可以避免循序掃描污染緩衝池快取,但這無助於降低 I/O 成本。
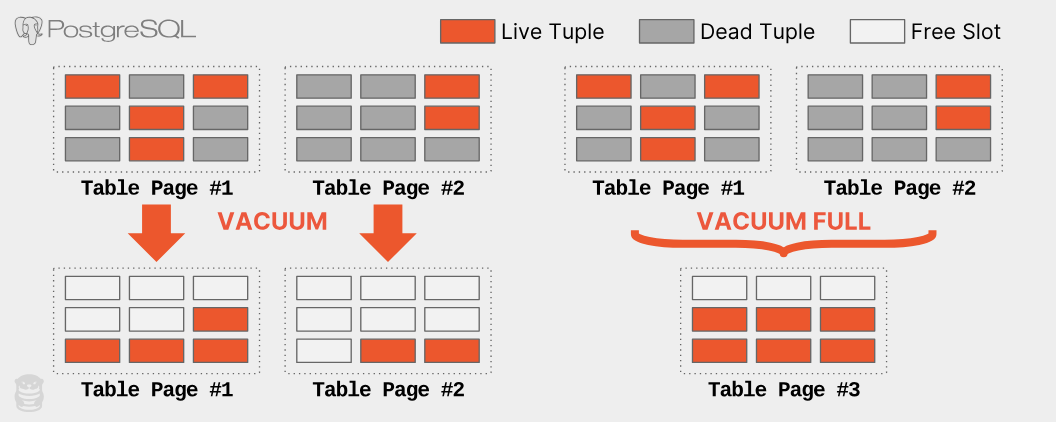
即使 PostgreSQL 的自動清理定期執行,而且可以跟上工作負載(這並不容易,詳見下文),自動清理也無法回收儲存空間。自動清理只會移除死亡資料列,並將活躍資料列重新排列到每個頁面的末尾,但不會回收磁碟上的空白頁面。
當 DBMS 因為沒有任何資料列而刪除最後一頁時,其他頁面仍然會留在磁碟上。在上述例子中,即使 PostgreSQL 移除了 40GB 的死亡資料列,它仍然會佔用作業系統(如果是 RDS ,則是 Amazon )配置的 50GB 儲存空間。要回收這些未使用的空間,必須使用 VACUUM FULL 或 pg_repack 擴充功能將整個表格重寫到新的空間,才不會浪費儲存空間。執行這些操作會嚴重影響生產環境資料庫的效能,需要仔細評估;它們是很耗費資源和時間的操作。下圖顯示 VACUUM 和 VACUUM FULL 的運作方式。
問題三:次要索引維護
更新單一資料列時,PostgreSQL 需要更新表格的所有索引。這是必要的,因為 PostgreSQL 的主索引和次要索引都使用版本的實體位置。除非 DBMS 將新版本儲存在與前一版本相同的頁面( HOT 更新),否則每次更新都必須這樣做。
回到 UPDATE 查詢的例子,PostgreSQL 會像之前一樣,複製原始版本到新的頁面來建立新版本。它也會在表格的主鍵索引( movies_pkey )和兩個次要索引( idx_director 、 idx_name )中插入指向新版本的項目。
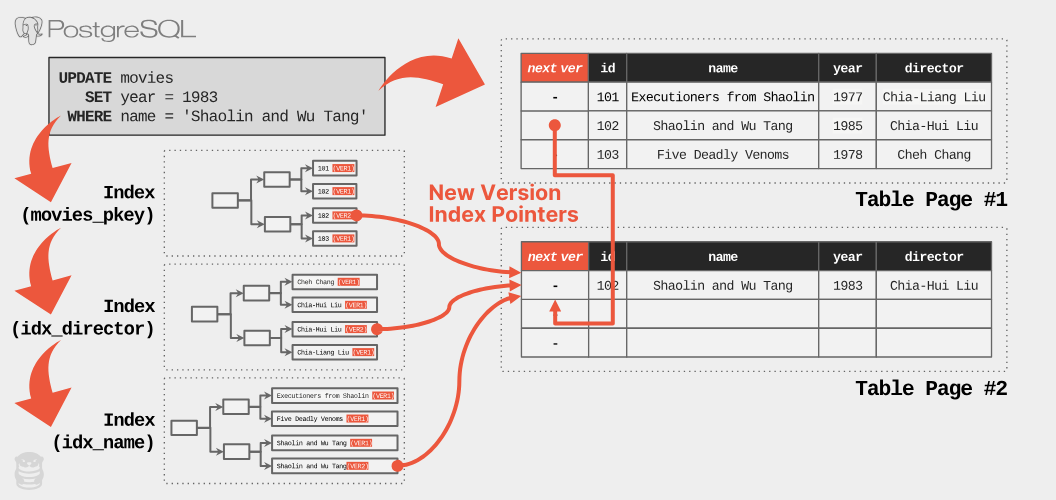
PostgreSQL 每次更新都需要修改所有索引,這會影響效能。更新查詢會變慢,因為系統需要做更多事。 DBMS 需要額外的 I/O 來走過每個索引並插入新項目。存取索引會在索引和 DBMS 的內部資料結構(例如:緩衝池的頁面表格)造成鎖定/閂鎖的競爭。 PostgreSQL 會對所有索引執行維護工作,即使查詢根本不會用到這些索引( OtterTune 可以自動找出資料庫中沒有用到的索引)。在 Amazon Aurora 等依 IOPS 計費的 DBMS 中,這些額外的讀寫操作會造成問題。
如前所述,如果 PostgreSQL 可以執行 HOT 寫入,將新版本寫入與目前版本相同的頁面,就可以避免每次更新都更新索引。根據我們對 OtterTune 客戶 PostgreSQL 資料庫的分析,平均約有 46% 的更新使用 HOT 優化。雖然這個數字很亮眼,但仍有超過 50% 的更新需要付出額外的代價。
有很多使用者因為 PostgreSQL MVCC 實作的這個問題而苦惱。最有名的例子就是 Uber 在 2016 年的部落格文章中說明他們為什麼從 PostgreSQL 轉換到 MySQL 。他們寫入頻繁的工作負載在有很多次要索引的表格上遇到嚴重的效能問題。
Oracle 和 MySQL 的 MVCC 實作沒有這個問題,因為它們的次要索引不儲存新版本的實體位址。它們儲存的是邏輯識別碼(例如:資料列 ID 、主鍵),DBMS 會用它來查找目前版本的實體位址。雖然這可能會讓次要索引讀取變慢,因為 DBMS 需要解析邏輯識別碼,但這些 DBMS 在 MVCC 實作上有其他優點可以降低負擔。
備註: Uber 的部落格文章中關於 PostgreSQL 版本儲存的說明有誤。 PostgreSQL 中的每個資料列儲存的是指向新版本的指標,而不是舊版本。這表示版本鏈的順序是 O2N ,而不是 Uber 錯誤宣稱的 N2O 。
問題四:清理管理
PostgreSQL 的效能很大程度上取決於自動清理移除過時資料和回收空間的效率(這就是為什麼 OtterTune 在您第一次連線資料庫時會立即檢查自動清理的健康狀態)。無論您使用的是 RDS 、Aurora 或 Aurora Serverless ,所有 PostgreSQL 版本都有相同的自動清理問題。但由於自動清理很複雜,要確保它盡可能地有效運作並不容易。 PostgreSQL 的自動清理預設設定並不適用於所有表格,尤其是大型表格。例如,控制 PostgreSQL 在觸發自動清理前需要更新多少比例資料列的設定參數( autovacuum_vacuum_scale_factor )預設值是 20% 。這表示,如果表格有 1 億列,在更新至少 2000 萬列之前,DBMS 不會觸發自動清理。因此,PostgreSQL 可能會在表格中保留大量死亡資料列很長一段時間(造成 I/O 和記憶體負擔)。
PostgreSQL 自動清理的另一個問題是它可能會被長時間執行的交易擋住,導致更多死亡資料列累積和統計資料過時。未能及時清理過期版本會導致許多效能問題,造成更多長時間執行的交易擋住自動清理程序。這會變成惡性循環,需要人工介入,手動終止長時間執行的交易。下圖顯示 OtterTune 客戶資料庫中兩週內的死亡資料列數量:
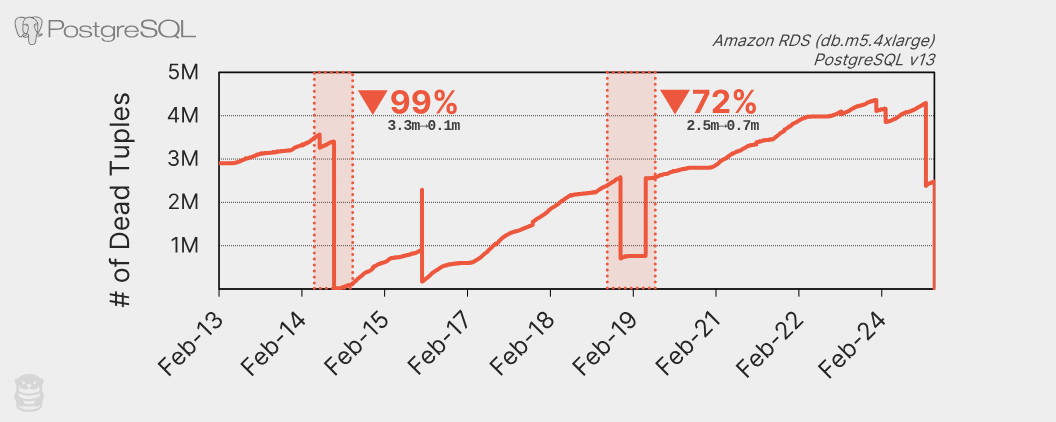
圖中的鋸齒狀圖案顯示自動清理大約每天會執行一次大規模清理。例如, 2 月 14 日清除了 320 萬列死亡資料列。這張圖其實是不健康的 PostgreSQL 資料庫的例子。圖中清楚顯示死亡資料列數量呈上升趨勢,因為自動清理的速度跟不上。
OtterTune 經常在客戶的資料庫中看到這個問題。某個 PostgreSQL RDS 執行個體因為大量插入資料後統計資料過時而導致查詢長時間執行。這個查詢擋住了自動清理更新統計資料,導致更多查詢長時間執行。 OtterTune 的自動健康檢查發現了這個問題,但管理員仍然需要手動終止查詢,並在大量插入資料後執行 ANALYZE 。好消息是,長時間執行的查詢從 52 分鐘縮短到 34 秒。
結語
設計 DBMS 時總會遇到一些困難的設計決策。這些決策會讓 DBMS 在不同工作負載下的效能表現不同。 Uber 的寫入密集型工作負載因為 PostgreSQL MVCC 造成的索引寫入放大問題而轉換到 MySQL 。但請不要誤會我們的意思,我們並不是說 PostgreSQL 完全不能用。雖然它的 MVCC 實作方式不好,PostgreSQL 仍然是我們最愛的 DBMS 。愛一個人就要包容他的缺點(參考 Dan Savage 的「 The Price of Admission 」)。
那麼,如何克服 PostgreSQL 的怪癖呢?您可以花大量的時間和精力自行調整。祝您好運。
我們會在下一篇文章中詳細說明我們可以做些什麼。




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}