
在 MySQL 中使用 UUID 作為主鍵的常見問題
了解 UUID 的不同版本,以及為何在 MySQL 中使用 UUID 的主鍵會影響資料庫效能。

作者: Brian Morrison II
用唯一識別碼(UUID)的設計宗旨是讓開發者在不了解其他系統的情況下,以確保唯一性的方式產生獨特的 ID。這在分散式架構中特別有用,因為你可能有多個負責建立記錄的系統和資料庫。你或許認為在資料庫中使用 UUID 作為主鍵是個好主意,但若使用不當,可能會嚴重影響資料庫效能。
本文將探討在 MySQL 資料庫中使用 UUID 作為主鍵的缺點。
UUID 的多個版本
截至撰寫本文時,共有五個正式版本的 UUID 和三個草案版本。讓我們逐一檢視每個版本,以更了解它們的運作方式。
UUIDv1
UUID 第 1 版稱為基於時間戳記的 UUID,可以拆解如下:

雖然現代計算大多使用 UNIX 紀元時間(1970 年 1 月 1 日)作為基準,但 UUID 實際上使用不同的日期:1582 年 10 月 15 日,這是格里高利曆開始被廣泛使用的日期。UUID 中嵌入的時間戳記從這個日期開始以 100 奈秒為單位遞增,然後用於設定 UUID 的 time_low、time_mid 和 time_hi 部分。
UUID 的第三部分包含 version,以及佔據該部分第一個字元的 time_hi。所有版本的 UUID 皆是如此,後續範例也會說明。reserved 部分也稱為 UUID 的變體,它決定了 UUID 中位元的用途。最後一部分是 node,即產生 UUID 的系統的唯一位址。
UUIDv2
與版本 1 相比,UUID 版本 2 的 time_low 部分被 POSIX 使用者 ID 取代。理論上,這些 UUID 可以追溯到產生它們的使用者 ID。由於 time_low 部分是 UUID 中變化最大的部分,取代這個部分會增加碰撞的機率。因此,這個版本的 UUID 很少使用。
UUIDv3 和 UUIDv5
版本 3 和版本 5 非常相似。這些版本的目標是允許以確定性的方式產生 UUID,讓相同的資訊能產生相同的 UUID。這些實作使用兩個資訊:命名空間(本身是一個 UUID)和名稱。這些值會透過雜湊演算法運算,以產生可表示為 UUID 的 128 位元值。
這兩個版本的主要差異在於版本 3 使用 MD5 雜湊演算法,而版本 5 使用 SHA1。
UUIDv4
版本 4 稱為隨機變體,因為它的值幾乎完全是隨機的。唯一的例外是 UUID 第三部分的第一個位置,它永遠是 4,表示使用的版本。

UUIDv6
版本 6 與版本 1 幾乎相同。唯一的差異是用於記錄時間戳記的位元被反轉,這代表時間戳記的最重要部分會先儲存。下圖顯示了這些差異:

這樣做的主要目的是建立與版本 1 相容的值,同時讓這些值更容易排序,因為時間戳記的最重要部分在前面。
UUIDv7
版本 7 也是基於時間戳記的 UUID 變體,但它整合了更常用的 Unix 紀元時間戳記,而不是版本 1 使用的格里高利曆日期。另一個主要區別是,節點(基於產生 UUID 的系統的值)被隨機性取代,讓這些 UUID 更難追溯到來源。
UUIDv8
版本 8 是最新版本,允許特定供應商的實作同時遵守 RFC 標準。UUIDv8 的唯一要求是版本必須在第三部分的第一個位置指定,就像所有其他版本一樣。
UUID 和 MySQL
使用 UUID(大多數情況下)可以保證架構中所有系統的唯一性,因此你可能會傾向將它們用作記錄的主鍵。但請注意,相較於自動遞增整數,這樣做有一些取捨。
插入效能
每次將新記錄插入 MySQL 表格時,都需要更新與主鍵相關的索引,以提升查詢表格的效能。MySQL 中的索引採用 B 樹形式,這是一種多層資料結構,允許查詢快速找到所需的資料。
下圖顯示了一個包含六個條目(值從 1 到 6)的簡化版本。如果查詢需要 5,MySQL 會從根節點開始,然後知道必須遍歷樹的右側才能找到目標。
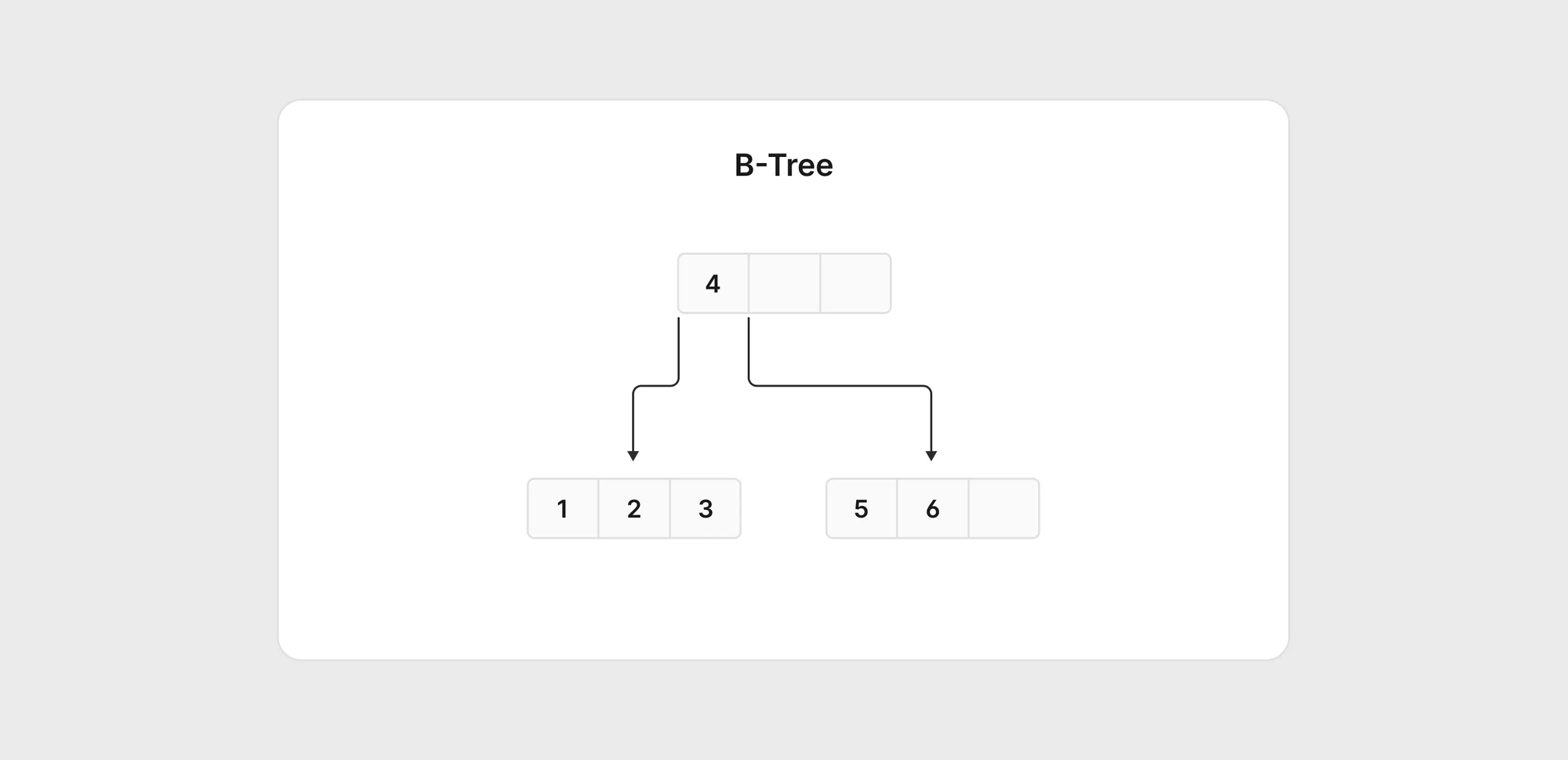
如果新增 7 到 9,MySQL 會分割右節點並重新平衡樹狀結構。
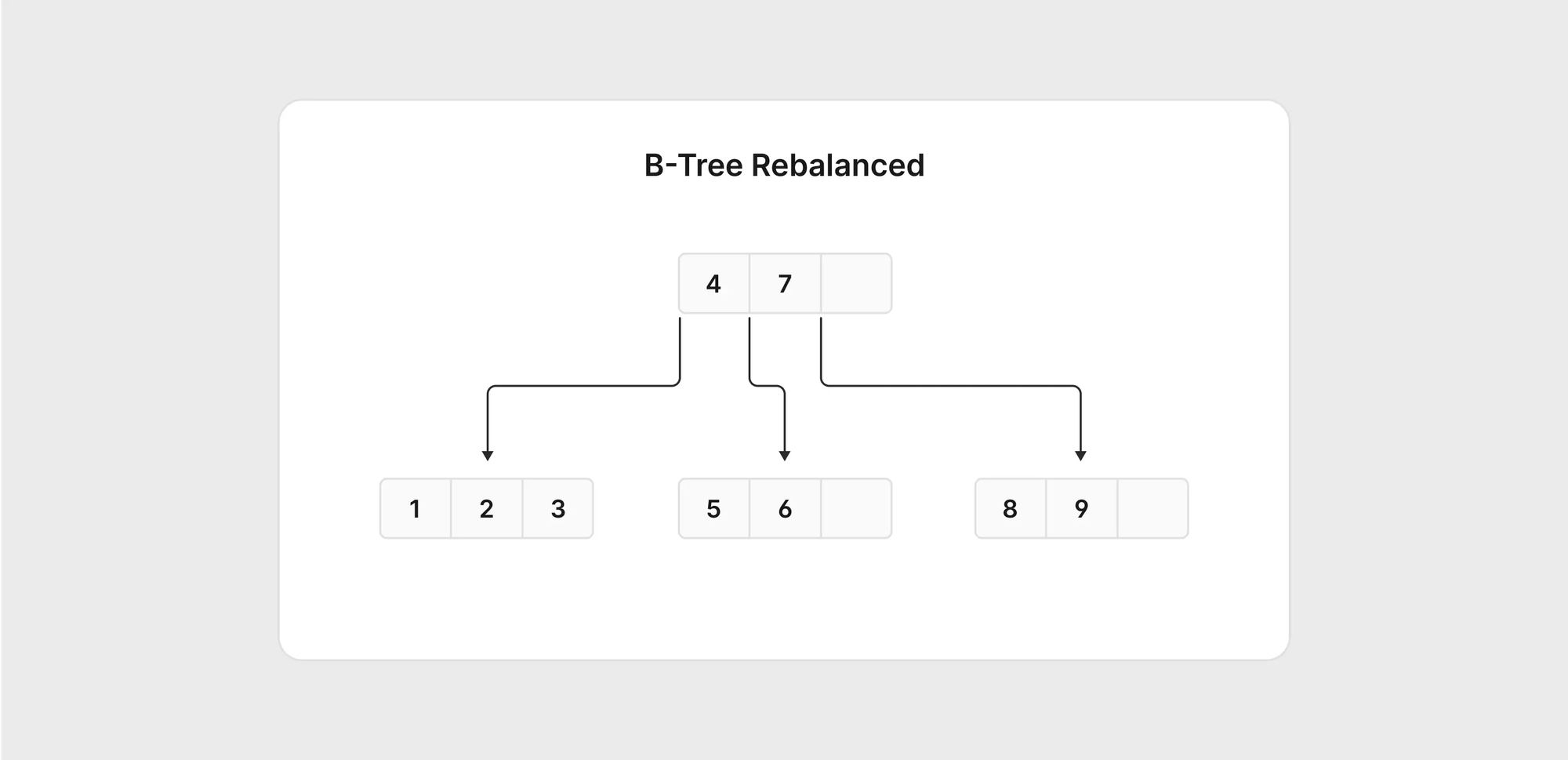
這個過程稱為頁面分割,目的是保持 B 樹結構平衡,讓 MySQL 能快速找到資料。對於連續值,這個過程相對簡單;然而,當演算法中引入隨機性時,MySQL 重新平衡樹狀結構可能需要更長時間。在高負載資料庫中,這可能會影響使用者體驗,因為 MySQL 會嘗試保持樹狀結構的平衡。
更高的儲存利用率
MySQL 中的所有主鍵都會建立索引。預設情況下,自動遞增整數的每個值會佔用 32 位元的儲存空間。相較之下,如果以緊湊的二進位格式儲存,單個 UUID 在磁碟上會佔用 128 位元,是 32 位元整數的 4 倍。如果選擇使用更易讀的基於字串的表示法,每個 UUID 可以儲存為 CHAR(36),每個 UUID 佔用高達 288 位元,是 32 位元整數的 9 倍。
除了主鍵上建立的預設索引外,次要索引也會佔用更多空間。這是因為次要索引使用主鍵作為指向實際資料列的指標,這表示它們需要與索引一起儲存。根據使用 UUID 作為主鍵的表格上建立的索引數量,這可能會導致資料庫的儲存需求顯著增加。
最後,頁面分割(如前節所述)也可能對儲存空間使用率造成負面影響,同時影響效能。InnoDB 假設主鍵會以可預測的方式遞增,無論是數值或字典順序。如果是這樣,InnoDB 會將頁面填滿到頁面大小的約 94% 才建立新頁面。當主鍵是隨機的時,每個頁面使用的空間可能低至 50%。因此,使用包含隨機性的 UUID 可能導致過度使用頁面來儲存索引。
在 MySQL 中使用 UUID 主鍵的最佳實務
如果必須使用 UUID 作為表格中記錄的唯一識別碼,可以參考以下幾個最佳實務,以盡量減少負面影響。
使用二進位資料類型
雖然 UUID 有時以 36 個字元的字串形式儲存,但它們也可以用原生二進位格式表示。如果轉換為二進位值,可以將其儲存在 BINARY(16) 欄位中,將每個值的儲存需求減少到 16 位元組。這仍然比 32 位元整數大得多,但肯定比將 UUID 儲存為 CHAR(36) 要好。
create table uuids(
UUIDAsChar char(36) not null,
UUIDAsBinary binary(16) not null
);
insert into uuids set
UUIDAsChar = 'd211ca18-d389-11ee-a506-0242ac120002',
UUIDAsBinary = UUID_TO_BIN('d211ca18-d389-11ee-a506-0242ac120002');
select * from uuids;
-- +--------------------------------------+------------------------------------+
-- | UUIDAsChar | UUIDAsBinary |
-- +--------------------------------------+------------------------------------+
-- | d211ca18-d389-11ee-a506-0242ac120002 | 0xD211CA18D38911EEA5060242AC120002 |
-- +--------------------------------------+------------------------------------+使用有序的 UUID 變體
使用支援排序的 UUID 版本可以減輕使用 UUID 的部分效能和儲存空間影響,因為產生的值更連續,避免了前面提到的部分頁面分割問題。即使在多個系統上產生,基於時間戳記的 UUID(例如版本 6 或版本 7)也能保證唯一性,同時保持值盡可能接近連續。UUIDv1 例外,因為它的時間戳記最不重要的部分在前面。
使用 MySQL 內建的 UUID
MySQL 直接支援在 SQL 中產生 UUID;然而,它只支援 UUIDv1 值。雖然單獨使用它們並非最佳做法,但 MySQL 有一個輔助函式 uuid_to_bin。這個函式不僅會將字串值轉換為二進位,你還可以搭配使用 swap flag 選項,它會重新排列時間戳記部分,讓產生的二進位值更連續。
set @uuidvar = 'd211ca18-d389-11ee-a506-0242ac120002';
-- Without swap flag
SELECT HEX(UUID_TO_BIN(@uuidvar)) as UUIDAsHex;
-- +----------------------------------+
-- | UUIDAsHex |
-- +----------------------------------+
-- | D211CA18D38911EEA5060242AC120002 |
-- +----------------------------------+
-- With swap flag
SELECT HEX(UUID_TO_BIN(@uuidvar,1)) as UUIDAsHex;
-- +----------------------------------+
-- | UUIDAsHex |
-- +----------------------------------+
-- | 11EED389D211CA18A5060242AC120002 |
-- +----------------------------------+使用替代 ID 類型
UUID 並非唯一一種在分散式架構中提供唯一性的識別碼類型。考量到它們最初創建於 1987 年,其他專家已經提出不同的格式,例如 Snowflake ID、ULID,甚至是 NanoID(我們在 PlanetScale 使用)。
# Snowflake ID
7167350074945572864
# ULID
01HQF2QXSW5EFKRC2YYCEXZK0N
# NanoID
kw2c0khavhql結論
在 MySQL 中使用 UUID 主鍵可以(幾乎)保證分散式系統中的唯一性;然而,它也伴隨著一些取捨。幸運的是,有許多版本和替代方案可供選擇,你可以選擇更能解決這些取捨的方案。閱讀本文後,你應該能夠在設計下一個資料庫時做出更明智的決策,選擇適合你的 ID 類型。



